class: center, middle background-image: url("Images/mlr/plate_spinners.jpg") # .white[Multiple Predictors in a Model] --- # So Many Ways to Build a Model 1. Multiple Predictors 2. Many Types of Categories 3. Many Models and Cross-Validation --- # Where we ended - One Predictor and Go! .large[ `$$y_i \sim \mathcal{N}(\widehat{y_i}, \sigma^2)\\ \widehat{y_i} = \beta_0 + \beta_1 x$$` ] <img src="many_predictors_files/figure-html/puffershow-1.png" alt="" style="display: block; margin: auto;" /> --- # Where we ended - This Model Works for Means! .large[ `$$y_i \sim \mathcal{N}(\widehat{y_i}, \sigma^2)\\ \widehat{y_i} = \beta_0 + \beta_1 x$$` ] <img src="many_predictors_files/figure-html/two_trts-1.png" alt="" style="display: block; margin: auto;" /> --- # Where we ended - Many Means, Many 0/1s! So.... Many Slopes? .large[ `$$y_{ij} \sim \mathcal{N}(\widehat{y_{ij}}, \sigma^2)\\ \widehat{y_{ij}} = \beta_0 + \sum\beta_j x_{ij}$$` ] <img src="many_predictors_files/figure-html/aovplot-1.png" alt="" style="display: block; margin: auto;" /> --- # One-Way ANOVA Graphically 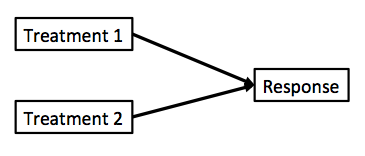 .large[ `$$y_{ij} \sim \mathcal{N}(\widehat{y_{ij}}, \sigma^2)\\ \widehat{y_{ij}} = \beta_0 + \sum\beta_j x_{ij}$$` ] --- # Multiple Linear Regression? 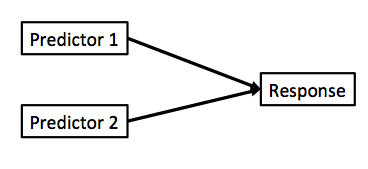 -- - Note no connection between predictors, as in ANOVA. -- - This is ONLY true if we have manipulated variables so that there is no relationship between the two. This is not often the case! --- # Multiple Linear Regression  -- - Curved double-headed arrow indicates COVARIANCE between predictors that we must account for. -- - MLR controls for the correlation - estimates unique contribution of each predictor controlling for the other. -- - I like to think of it as holding the other predictor at its mean, or 0, or anything! --- # Multiple Linear Regression - We've Seen This Before! .large[ `$$y_{i} \sim \mathcal{N}(\widehat{y_{i}}, \sigma^2)\\ \widehat{y_{i}} = \beta_0 + \sum\beta_j x_{ij}$$` ]  --- background-image: url("Images/mlr/fires.jpg") background-size: cover <div style="bottom:100%; text-align:left; background:goldenrod"><h4>Five year study of wildfires & recovery in Southern California shur- blands in 1993. 90 plots (20 x 50m)</h4> (data from Jon Keeley et al.)</div> --- # What causes species richness? - Distance from fire patch - Elevation - Abiotic index - Patch age - Patch heterogeneity - Severity of last fire - Plant cover --- # Many Things may Influence Species Richness <img src="many_predictors_files/figure-html/keeley_pairs-1.png" alt="" style="display: block; margin: auto;" /> --- # Our Model `$$Richness_i \sim \mathcal{N}(\widehat{Richness_i}, \sigma^2)\\ \widehat{Richness_i} =\beta_{0} + \beta_{1} cover +\beta_{2} firesev + \beta_{3}hetero$$` <img src="many_predictors_files/figure-html/dagmlr-1.png" alt="" style="display: block; margin: auto;" /> --- # Fit with Our Engine: Ordinary Least Squares ### It's just another linear model! .large[ ``` r klm <- lm(rich ~ cover + firesev + hetero, data=keeley) ``` ] --- # Does Your Model Match Your Data? <img src="many_predictors_files/figure-html/ggplot_dist-1.png" alt="" style="display: block; margin: auto;" /> --- # Are There Weird Patterns in Your Residuals? <img src="many_predictors_files/figure-html/mlr_resid-1.png" alt="" style="display: block; margin: auto;" /> ---  If your predictors are correlated at > 0.8.... are they really independent predictors? --- # The Variance Inflation Factor <img src="many_predictors_files/figure-html/multico-1.png" alt="" style="display: block; margin: auto;" /> -- - Basically, you look at how much all predictors explain each other ( `\(R^2\)` of lots of mlr fits) -- - 5-10 is... not good. Greater, you have set fire to your inferential train --- # What To Do If You've Caused a Fire -- - Cry -- - Drop a predictor -- - Transform a predictor, if it is appropriate --- # Did Our PredictorS Matter? F = (MS model with predictor - MS model without)/MS Residual <br> Where MS is a measure of variability (Sums of squares/DF) <table class="table table-striped" style="color: black; margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="text-align:left;"> term </th> <th style="text-align:right;"> sumsq </th> <th style="text-align:right;"> df </th> <th style="text-align:right;"> statistic </th> <th style="text-align:right;"> p.value </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> cover </td> <td style="text-align:right;"> 1674.18 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 12.01 </td> <td style="text-align:right;"> 0.00 </td> </tr> <tr> <td style="text-align:left;"> firesev </td> <td style="text-align:right;"> 635.65 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 4.56 </td> <td style="text-align:right;"> 0.04 </td> </tr> <tr> <td style="text-align:left;"> hetero </td> <td style="text-align:right;"> 4864.52 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 34.91 </td> <td style="text-align:right;"> 0.00 </td> </tr> <tr> <td style="text-align:left;"> Residuals </td> <td style="text-align:right;"> 11984.57 </td> <td style="text-align:right;"> 86 </td> <td style="text-align:right;"> NA </td> <td style="text-align:right;"> NA </td> </tr> </tbody> </table> --- # What are the Coefficients? <table class="table table-striped" style="color: black; margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="text-align:left;"> term </th> <th style="text-align:right;"> estimate </th> <th style="text-align:right;"> std.error </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> (Intercept) </td> <td style="text-align:right;"> 1.68 </td> <td style="text-align:right;"> 10.67 </td> </tr> <tr> <td style="text-align:left;"> cover </td> <td style="text-align:right;"> 15.56 </td> <td style="text-align:right;"> 4.49 </td> </tr> <tr> <td style="text-align:left;"> firesev </td> <td style="text-align:right;"> -1.82 </td> <td style="text-align:right;"> 0.85 </td> </tr> <tr> <td style="text-align:left;"> hetero </td> <td style="text-align:right;"> 65.99 </td> <td style="text-align:right;"> 11.17 </td> </tr> </tbody> </table> - **Intercept:** If all predictors are 0, a plot will have 1.68 species approach on average. -- - **Cover:** Holding fire severity and heterogeneity constant, a 1 unit increase in cover is associated with an increase in 15.6 species -- - **Fire Severity:** Holding cover and heterogeneity constant, a 1 unit increase in fire severity is associated with an loss of 1.82 species -- - **Heterogeneity:** Holding fire severity and cover constant, a 1 unit increase in heterogeneity is associated with an increase in 70 species --- # Visualize Each Predictor Holding Others at the Median or Mean <img src="many_predictors_files/figure-html/visreg-1.png" alt="" style="display: block; margin: auto;" /> --- # Or Build a Plot That Shows the Implication of Selecting Certain Values - a Counterfactual Plot <img src="many_predictors_files/figure-html/counterfact-1.png" alt="" style="display: block; margin: auto;" /> --- # So Many Ways to Build a Model 1. Multiple Predictors 2. .red[ Many Types of Categories ] 3. Many Models and Cross-Validation --- class: center, middle  --- # Compare These Models ### Multiple Linear Regression: `$$y_{i} \sim N(\widehat{y_{i}}, \sigma^{2} )$$` `$$\widehat{y_{i}} = \beta_{0} + \sum \beta_{j}x_{ij}$$` ### Mutiway ANOVA: `$$y_{ijk} \sim N(\widehat{y_{ijk}}, \sigma^{2} )$$` `$$\widehat{y_{ijk}} = \beta_{0} + \sum \beta_{ij}x_{ij} + \sum \beta_{ik}x_{ik}$$` `$$x_{ij} \; \mathrm{and} \; x_{ik} = 0,1$$` --- # Multiway Model = More Than One Treatment Type ## For example: A Randomized Controlled Blocked Design  --- # Effects of Stickleback Density on Zooplankton Replicated in Different Lakes (Blocks) <br><br> .pull-left[  ] .pull-right[  ] --- # Effects of Both Treatment and Block <img src="many_predictors_files/figure-html/zooplankton_boxplot-1.png" alt="" style="display: block; margin: auto;" /> --- # It's All 0s and 1s Data Prepped for Model <table class="table table-striped" style="color: black; margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="text-align:right;"> treatmentcontrol </th> <th style="text-align:right;"> treatmenthigh </th> <th style="text-align:right;"> treatmentlow </th> <th style="text-align:right;"> block2 </th> <th style="text-align:right;"> block3 </th> <th style="text-align:right;"> block4 </th> <th style="text-align:right;"> block5 </th> </tr> </thead> <tbody> <tr> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0 </td> </tr> <tr> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0 </td> </tr> <tr> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0 </td> </tr> <tr> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0 </td> </tr> <tr> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0 </td> </tr> <tr> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 0 </td> </tr> </tbody> </table> --- # Put it to the Test: F-Test <table class="table table-striped" style="color: black; margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="text-align:left;"> term </th> <th style="text-align:right;"> df </th> <th style="text-align:right;"> sumsq </th> <th style="text-align:right;"> meansq </th> <th style="text-align:right;"> F </th> <th style="text-align:right;"> p.value </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> treatment </td> <td style="text-align:right;"> 2 </td> <td style="text-align:right;"> 6.857 </td> <td style="text-align:right;"> 3.429 </td> <td style="text-align:right;"> 16.366 </td> <td style="text-align:right;"> 0.001 </td> </tr> <tr> <td style="text-align:left;"> block </td> <td style="text-align:right;"> 4 </td> <td style="text-align:right;"> 2.340 </td> <td style="text-align:right;"> 0.585 </td> <td style="text-align:right;"> 2.792 </td> <td style="text-align:right;"> 0.101 </td> </tr> <tr> <td style="text-align:left;"> Residuals </td> <td style="text-align:right;"> 8 </td> <td style="text-align:right;"> 1.676 </td> <td style="text-align:right;"> 0.209 </td> <td style="text-align:right;"> NA </td> <td style="text-align:right;"> NA </td> </tr> </tbody> </table> `\(R^2\)` = 0.846 --- # Comparison of Differences at Average of Other Treatment(s) <table class="table table-striped" style="color: black; margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="text-align:left;"> contrast </th> <th style="text-align:right;"> estimate </th> <th style="text-align:right;"> SE </th> <th style="text-align:right;"> df </th> <th style="text-align:right;"> t.ratio </th> <th style="text-align:right;"> p.value </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> control - high </td> <td style="text-align:right;"> 1.64 </td> <td style="text-align:right;"> 0.289 </td> <td style="text-align:right;"> 8 </td> <td style="text-align:right;"> 5.665 </td> <td style="text-align:right;"> 0.001 </td> </tr> <tr> <td style="text-align:left;"> control - low </td> <td style="text-align:right;"> 1.02 </td> <td style="text-align:right;"> 0.289 </td> <td style="text-align:right;"> 8 </td> <td style="text-align:right;"> 3.524 </td> <td style="text-align:right;"> 0.019 </td> </tr> <tr> <td style="text-align:left;"> high - low </td> <td style="text-align:right;"> -0.62 </td> <td style="text-align:right;"> 0.289 </td> <td style="text-align:right;"> 8 </td> <td style="text-align:right;"> -2.142 </td> <td style="text-align:right;"> 0.142 </td> </tr> </tbody> </table> --- # And a Plot! <img src="many_predictors_files/figure-html/plot_zoop_em-1.png" alt="" style="display: block; margin: auto;" /> --- # If you really wanted to... <img src="many_predictors_files/figure-html/plot_zoop_em_2-1.png" alt="" style="display: block; margin: auto;" /> --- # So Many Ways to Build a Model 1. Multiple Predictors 2. Many Types of Categories 3. .red[Many Models and Cross-Validation] --- background-image: url("Images/mlr/fires.jpg") background-size: cover <div style="bottom:100%; text-align:left; background:goldenrod"><h4>Five year study of wildfires & recovery in Southern California shur- blands in 1993. 90 plots (20 x 50m)</h4> (data from Jon Keeley et al.)</div> --- # What causes species richness? - Distance from fire patch - Elevation - Abiotic index - Patch age - Patch heterogeneity - Severity of last fire - Plant cover --- # WHAT PREDICTORS SHOULD I USE?  --- # The Second Inferential Track!  ![:col_header Hypothesis Testing, Model Comparison, Bayesian Model Implications ] -- ![:col_list Deductive Inference, Predictive Inference, Inductive Inference ] -- ![:col_list Uses probabilities of overlap with a point hypothesis, Uses tests of model performances on new data, Uses probability distributions of parameters and simulation ] --- # Predictive Ability: A Way to Differentiate Between Model Performance - Fit of a model seems like a good place to start... -- - BUT - `\(R^2\)` is specific to the data *you used to fit the model. -- - We need something more objective! -- - How about how well our model does at predicting new data? --- # But we Don't HAVE any New Data: Training, Testing, and Cross-Validation 1. Fit a model on a **training** data set 2. Evaluate a Model on a **TEST** data set 3. Compare predictive ability of competing models with MSE, Deviance, etc. --- # Common Out of Sample Metrics `\(MSE = \frac{1}{n}\sum{(Y_i - \hat{Y})^2}\)` - In units of sums of squares `\(RMSE = \sqrt{\frac{1}{n}\sum{(Y_i - \hat{Y})^2}}\)` - In units of response variable! - Estimate of SD of out of sample predictions `\(Deviance = -2 \sum log(\space p(Y_i | \hat{Y}, \theta)\space)\)` - Probability-based - Encompasses a wide number of probability distributions - Just MSE for gaussian linear models! --- # But.... what data do I use for training and testing? ## Random Cross-Validation - Cross-validating on only one point could be biased by choice of poing - So, choose a random subset of your data! - Typically use a 60:40 split, or 70:30 for lower sample size - Calculate fit metrics for alternate models and compare --- # For Example...Leave Out One Row of the Keeley Data `$$Richness_i \sim \mathcal{N}(\widehat{Richness_i}, \sigma^2)\\ \widehat{Richness_i} =\beta_{0} + \beta_{1} cover +\beta_{2} firesev + \beta_{3}hetero$$` <img src="many_predictors_files/figure-html/unnamed-chunk-2-1.png" alt="" style="display: block; margin: auto;" /> --- # Or, Compare Two Models Leaving out 30% of the Data At Random ``` r split_dat <- initial_split(keeley, prop = 0.7) mod_a <- lm(rich ~ cover + firesev + hetero, data = training(split_dat)) mod_b <- lm(rich ~ cover, data = training(split_dat)) ``` <img src="many_predictors_files/figure-html/unnamed-chunk-4-1.png" alt="" style="display: block; margin: auto;" /> --- class: center, middle # But, wait, what if I choose a bad section of the data by chance? --- # K-Fold Cross Validation - Data is split into K sets of training and testing folds - Performance is averaged over all sets 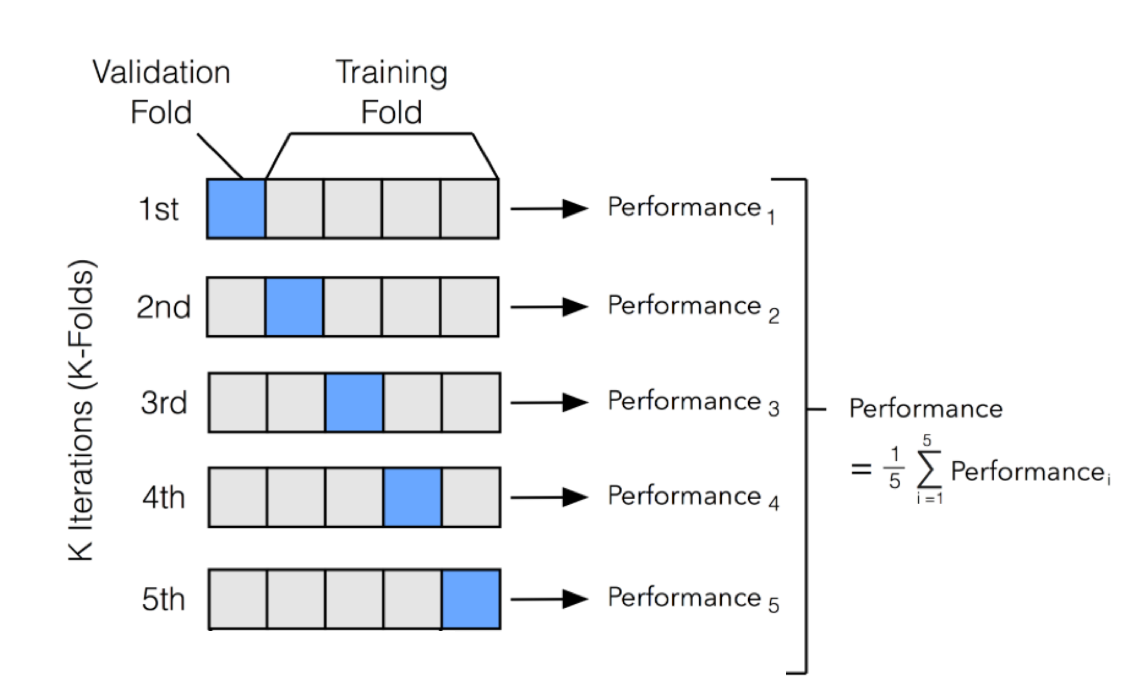 --- # Five-Fold CV |id | mse_all| mse_cover| |:-----|---------:|---------:| |Fold1 | 94.25348| 250.9335| |Fold2 | 190.27080| 308.0340| |Fold3 | 204.84293| 130.2679| |Fold4 | 196.50758| 239.8989| |Fold5 | 118.88828| 167.7846| All Predictors Model Score: 160.952613 Cover Only Score: 219.3837719 --- # Problem: How Many Folds? - What is a good number? - More folds = smaller test dataset - Bias-Variance tradeoff if also looking at coefficients -- - 5 and 10 are fairly standard, depending on data set size -- - More folds = closer to average out of sample error -- - But, more folds can be computationally intensive -- - Still, Leave One Out Cross Validation is very powerful --- # LOOCV (Leave One Out Cross-Validation) <br><br> 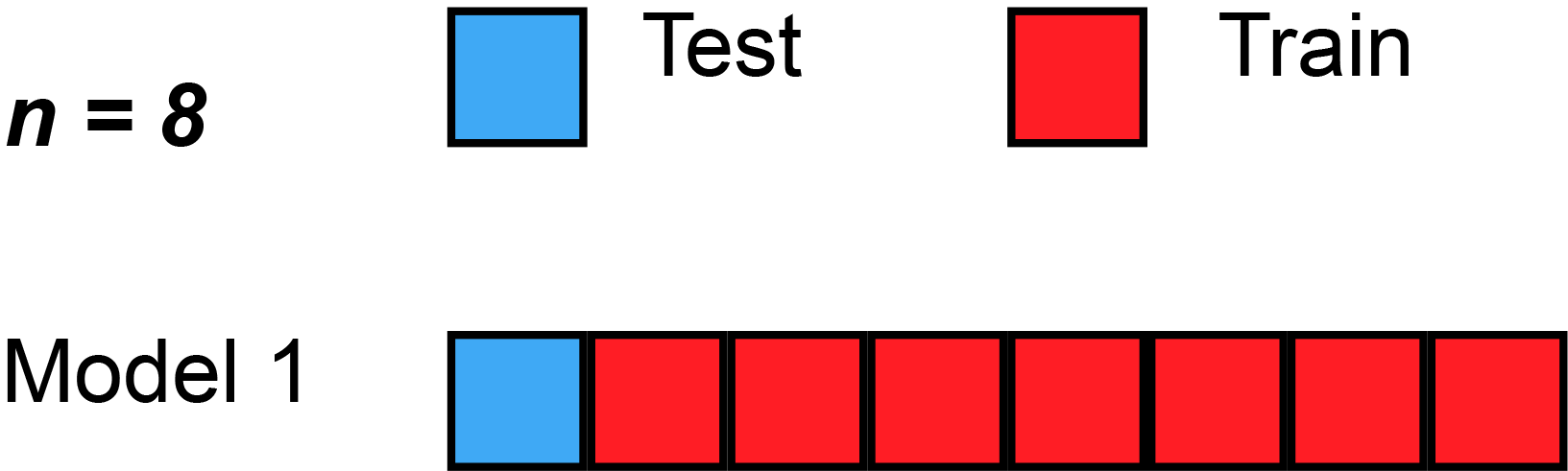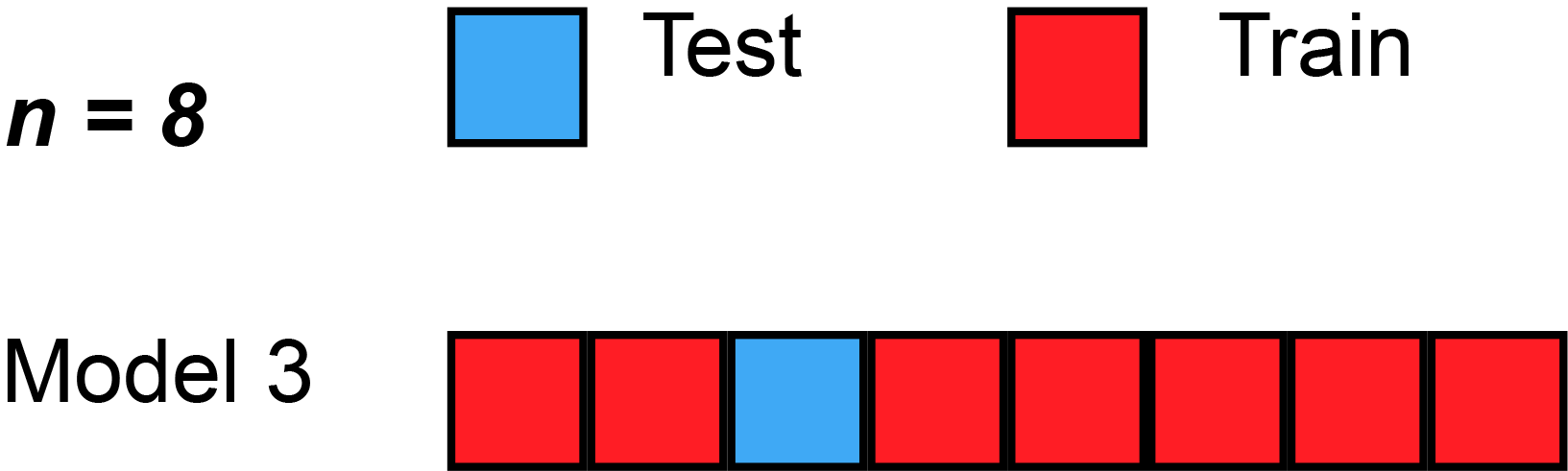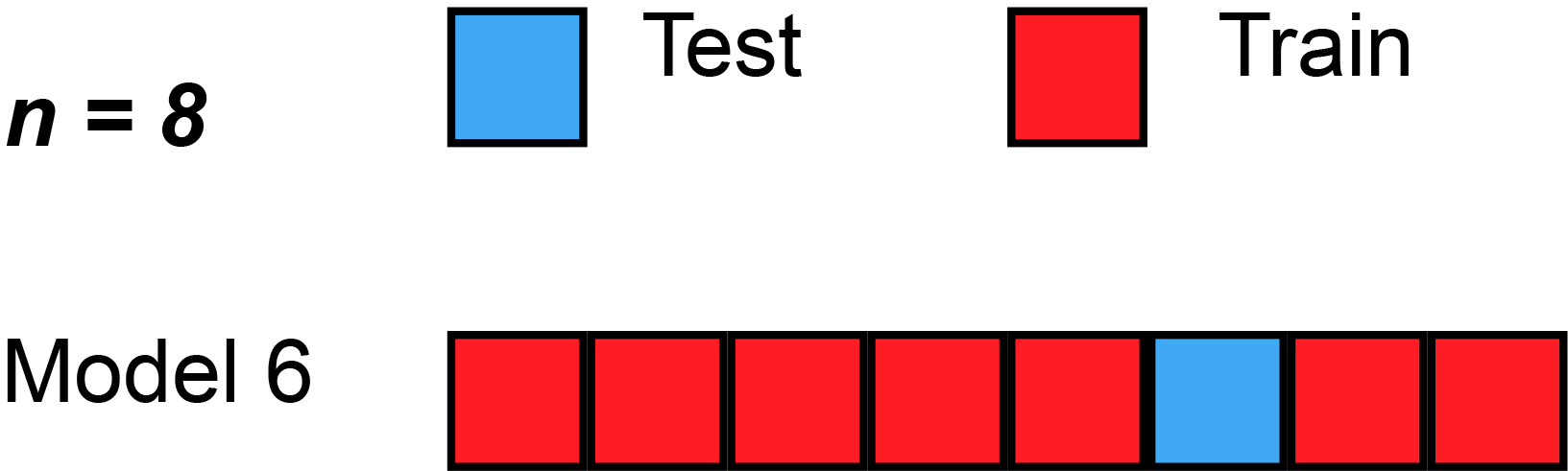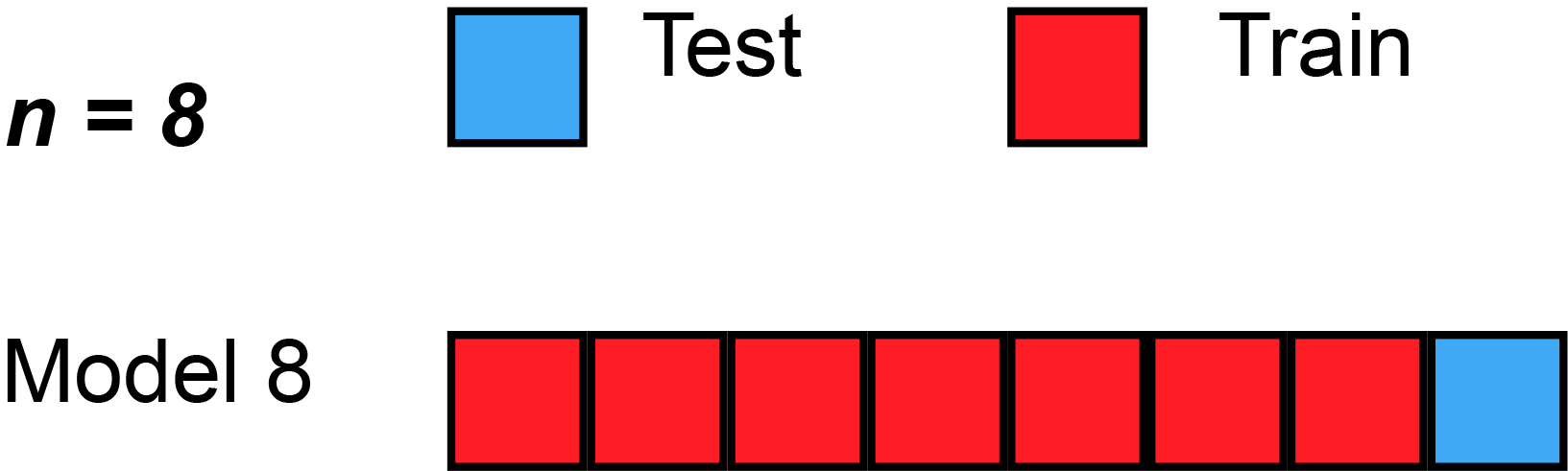 --- # LOOCV Comparison of Out of Sample Deviance (MSE) <br><br> All Predictor Model:144.78 Cover Only Model: 210.27 --- class: center, middle # What if We Have 10e10 Data Points or Many Many Models? --- # A Funny Thing Happens As You Increase Parameters in a Model... <img src="many_predictors_files/figure-html/traintest_plot-1.png" alt="" style="display: block; margin: auto;" /> --- # Enter the AIC .pull-left[  ] .pull-right[ - `\(E[D_{test}] = D_{train} + 2K\)` - This is Akaike's Information Criteria (AIC) ] `$$\Large AIC = Deviance + 2K$$` --- # AIC and Prediction - AIC optimized for forecasting (out of sample deviance) - Approximates average out of sample deviance from test data - Assumes large N relative to K - AICc for a correction --- # AIC Tables Give us Weight of Evidence for Different Models ``` r klm <- lm(rich ~ cover + firesev + hetero, data=keeley) klm_cover <- lm(rich ~ cover, data=keeley) klm_firesev <- lm(rich ~ firesev, data=keeley) klm_hetero <- lm(rich ~ hetero, data=keeley) ``` <table class="table table-striped" style="color: black; margin-left: auto; margin-right: auto;"> <thead> <tr> <th style="text-align:left;"> Modnames </th> <th style="text-align:right;"> K </th> <th style="text-align:right;"> AIC </th> <th style="text-align:right;"> Delta_AIC </th> <th style="text-align:right;"> AICWt </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> All predictors </td> <td style="text-align:right;"> 5 </td> <td style="text-align:right;"> 705.65 </td> <td style="text-align:right;"> 0.00 </td> <td style="text-align:right;"> 1 </td> </tr> <tr> <td style="text-align:left;"> heterogeneity </td> <td style="text-align:right;"> 3 </td> <td style="text-align:right;"> 728.03 </td> <td style="text-align:right;"> 22.38 </td> <td style="text-align:right;"> 0 </td> </tr> <tr> <td style="text-align:left;"> fire </td> <td style="text-align:right;"> 3 </td> <td style="text-align:right;"> 736.03 </td> <td style="text-align:right;"> 30.38 </td> <td style="text-align:right;"> 0 </td> </tr> <tr> <td style="text-align:left;"> cover </td> <td style="text-align:right;"> 3 </td> <td style="text-align:right;"> 738.80 </td> <td style="text-align:right;"> 33.15 </td> <td style="text-align:right;"> 0 </td> </tr> </tbody> </table> --- # We Have Visisted the Second Track!  ![:col_header Hypothesis Testing, Model Comparison, Bayesian Model Implications ] -- ![:col_list Deductive Inference, Predictive Inference, Inductive Inference ] -- ![:col_list Uses probabilities of overlap with a point hypothesis, Uses tests of model performances on new data, Uses probability distributions of parameters and simulation ] --- # Final Thoughts on Cross-Validation and Model Selection - Make sure your model meets assumptions before including it in a set to be evaluated! Don't set fire to your inferential train!! -- - Prediction is not always your goal! -- - A model can be predictive but not have causal meaning -- - BUT - prediction is highly useful for real-world application -- - In working with users, CV approaches can help them gain insight into which models to use in order to guide their choices